Pop-Diffuseq paper supplement and generated samples
Welcome to the supplement page!
POP-Diffuseq, the digital music content infilling in Midi format. The audio samples on this page are exported from Apple Logic build-in sounds.
Implement code are available on Github:
https://github.com/musicai-cakecake/pop-diffuseq
The trained models, datasets and all unfiltered samples can be downloaded in Google Drive:
https://drive.google.com/drive/folders/1OWI_sfYmYn2gB13KccO9kkXCP2x8Z-1x?usp=drive_link
Our MIDI dataset PopBand3k are also in this link.

Figure 1. Pop-Diffuseq: Conditional pop music accompaniment generation. POP-Diffuseq can create pop music scores
guided by musical terms(prompts) such as instrument and tempo, and is qualified to any-to-any instruments generation.
Method and pipeline model configurations
We present POP-Diffuseq, a pop music infilling model based on classifier-free discrete diffusion. In this work, the midi content (such pitch,onset,duration etc.) is encoded in a syntax pattern of Structure-Aligned (SA) tensor, where rows represent note (chord) units and columns express the attributes of the notes (chords). The encoded tensors will be trained and inferred by the deep learning model. Of course, the music score (midi file) is decoded from inferred tensor via the Structure-Aligned (SA) grammar pattern. The pipeline is shown in Figure 2. This approach is called “representation learning” in textual and symbolic music research.
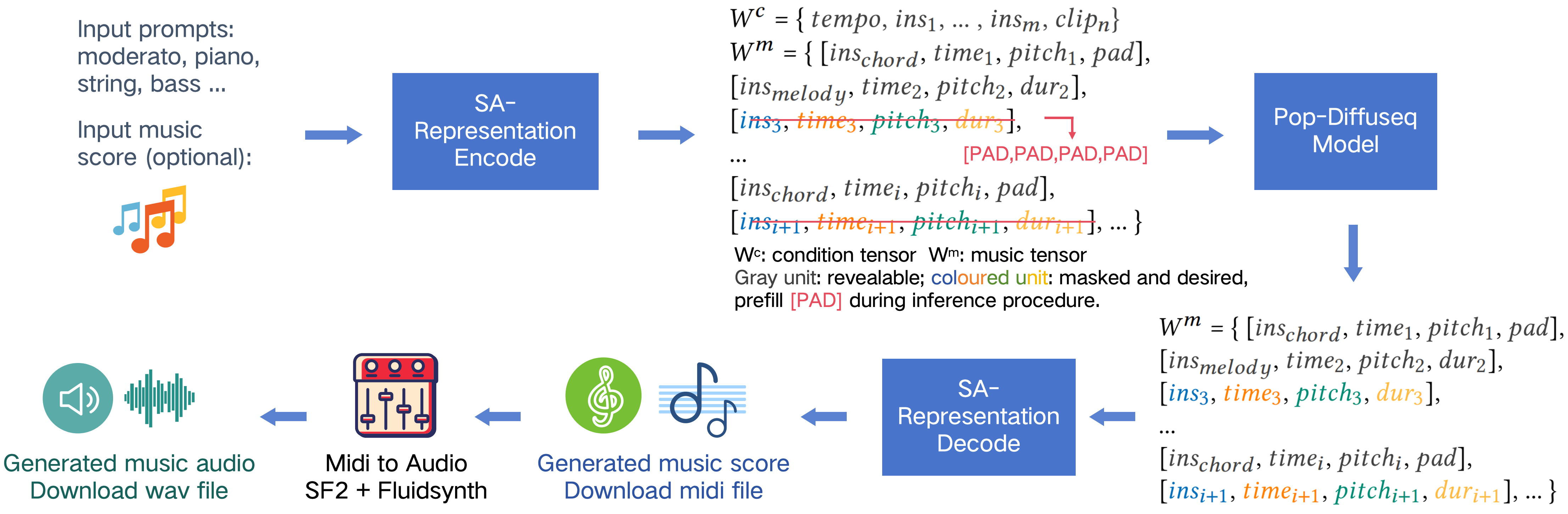
Figure 2. Method and pipeline of training and inference.
The greatest value of this infilling method is to support the human-intelligent interaction of Artificial Intelligence Generated Content (AIGC).
Some typical scenarios are shown in Figure 3.
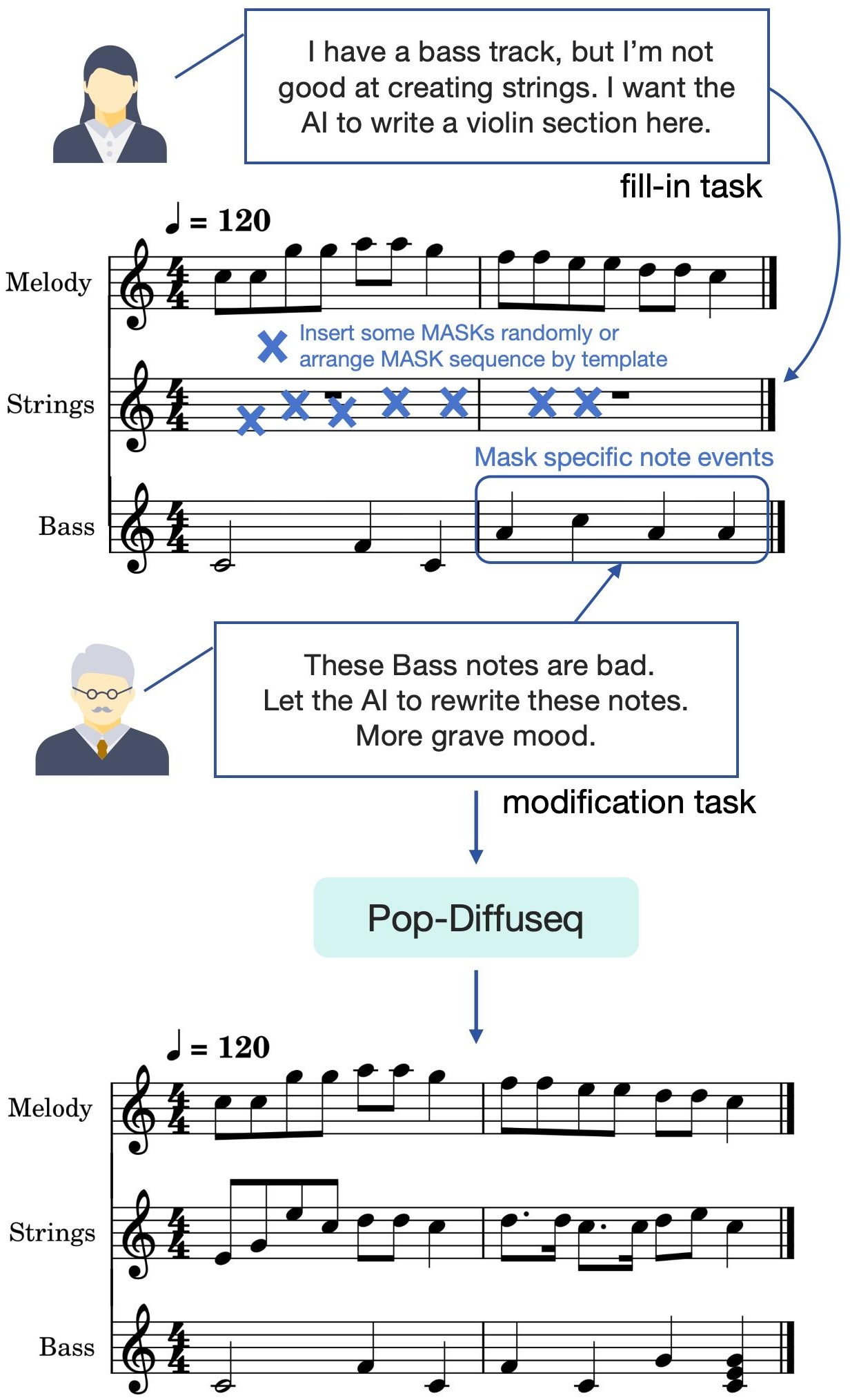
Figure 3. Interactive generation by Pop-diffuseq.
Piano and chord conditioned melody generation samples (accompaniment to melody)
Generate melody based on a given piano track.
Data set: Pop909.
| Samples | Input | AI Generation | Human Ground truth |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 | |||
| Sample 4 | |||
| Sample 5 | |||
| Sample 6 | |||
| Sample 7 |
Prompts and chord conditioned accompaniment generation samples (prompts and melody to accompaniment)
Generate band accompaniment from specified instruments and tempo prompts.
Data set: PopBand3k
| Samples | Input prompts | Input melody | AI generation |
|---|---|---|---|
| Sample 1 | Guitar, bass, ensemble, drum, percussive, Tempo-Andante | ||
| Sample 2 | Ethnic, bass, guitar, drum, synth-pad, Tempo-Andante | ||
| Sample 3 | Brass, bass, synth-pad, drum, ensemble, Tempo-Moderato | ||
| Sample 4 | Strings, bass, guitar, piano, Tempo-Andante | ||
| Sample 5 | Guitar, bass, piano, drum, organ, Tempo-Allegro |
Data set: LMD Masking strategy: high yield
| Samples | Input prompts | Input melody | AI generation |
|---|---|---|---|
| Sample 1 | Electric guitar, bass, drum, Tempo-Moderato | ||
| Sample 2 | Brass, bass, drum, percussive, Tempo-Andante | ||
| Sample 3 | Acoustic guitar, bass, drum, piano, Tempo-Allegro | ||
| Sample 4 | Ensemble, synth pad, percussive, Tempo-Moderato | ||
| Sample 5 | Ensemble, bass, drum, Tempo-Andante | ||
| Sample 6 | Acoustic guitar, electric guitar, bass, percussive, Tempo-Andante | ||
| Sample 7 | Brass, bass, percussive, Tempo-Allegro | ||
| Sample 8 | electric guitar, bass, percussive, Tempo-Allegro |
Contrast
| Samples | Input melody | POPMAG | Our Pop-Diffuseq |
|---|---|---|---|
| Sample 1 | |||
| Sample 2 | |||
| Sample 3 |
Interactive generation
| Original music | Fill-in drum |
|---|---|
| Original music | Original guitar and bass | AI modified guitar and bass | Modified music |
|---|---|---|---|
Dataset and preprocessing
As stated in the paper, We contribute a pop band MIDI dataset MidiPopBand3k and a modified LMD-matched(LMD) dataset, both of which were used for experiments.
MidiPopBand3k is a well-chosen collection of 1000 pop MIDI music carefully selected by our musicians. All 1K raw MIDI files in the dataset are obtained from free Internet sources.
We then split the music into shorter pieces, resulting in 3K MIDI files. Although the length of music in small clips is shortened, it is sufficient for various music AI tasks.
The music collection is carefully selected based on a series of criteria:
(1) Pop band music. The music must include a vocal melody track and at least three different instrumental accompaniments. In other words, music has at least four parts.
(2) The entire music must be long enough to be divided into three segments, each of at least 500 notes.
(3) The category of musical instrument are distinct enough to be identified in all tracks.
(4) Musical styles range from classic pop, rock, jazz and country etc. Try to avoid rap and electronic music as they are not easy to study together.
Oriental music (including Chinese pop, J-pop, K-pop and a small amount of Indian pop) accounts for a larger proportion.
Our musicians manually annotated the instrument category on each track and proofread the tempo of all the music. MidiPopBand3k is suitable for various AI tasks, including music generation, understanding and recommendation. We make MidiPopBand3k freely available to help research in the field of music artificial intelligence. The design of instrument categories and tempo will be introduced in subsequent chapters.
LMD-matched is a POP subset of Lakh MIDI dataset(colinraffel.com/projects/lmd), the subset have been matched to entries in the Million Song Dataset.
The style of LMD-aligned include folk pop, metal pop, Rock and roll, jazz pop, traditional pop etc., most music belong to western pop music.
The raw MIDI files are very coarse, have much of mistake in music content, such as no melody, superposition of notes, unaligned beat, empty track or merged track, no instrument label etc. A poor data set will seriously affect the training quality of the model.
Some of other AI music works not released the processed midi samples or artificially trim the MIDI data, however, manually processing MIDI content on big data is impossible. For general AI tasks, We contribute a series of algorithms for automatically preprocessing and trimming MIDI content based on music theory.
These implementation tools are suitable for most types of music and can easily expand big data.
Following the same screening criteria and processing procedures as MidiPopBand3k, we finally filtered out a modified LMD dataset of 14K+ MIDI files.
Model configurations
In order to fairly demonstrate the contributions of the representation, attention algorithm and framework proposed in this paper, the bidirectional encoder structures of our Pop-Diffuseq and Diffuseq comparison group both adopt the benchmark configuration ’bert-base-uncased’ of Hugging-face. Moreover, the hyperparameters and training data are also required to be exactly the same. We set the length of a sequence to 512, which contains 125 notes, 7 prompts and 5 special symbols. 4 sequences are spliced into one piece of music. The hidden size of encoder layers are 768, which is assigned to 12 attention heads. Four output linear layers are shared parameters(actually reuse one dense network in program coding). We employ many accelerated approaches for both the training and sampling stages, such as the fast ODE solver(DPM-solver) for diffusion model, FP16 for GPU acceleration and AI platform Pytorch2.0. The diffusion steps in training stage are 2000, 10 steps in decoding stage. Sqrt noise schedule are used in training stage. We train Pop-Diffuseq model and comparison group on 4 NVIDIA 4090 GPUs, with batch size of 40 sequence. It takes 40k steps for training until convergence.
Supplement for music representation
Instrument
We adopt all 16 instrument categories according to the MIDI protocol, then divide the guitar into acoustic guitar and electric guitar, and finally the vocal melody track, a total of 18 categories.
All existing musical instruments and sounds are classified into these 18 categories:
| Instrument Category | Timbre Cases (program number) | Instrument Category | Timbre Cases (program number) |
|---|---|---|---|
| Melody | grand piano(0) | Chord progression | grand piano(0) |
| Piano | grand piano(0), Honky-tonk piano(3) | Chromatic percussion | marimba(12), xylophone(13) |
| Organ | accordion(21), church organ(19) | Bass | acoustic bass(32), electric bass(33) |
| Acoustic guitar | nylon(24), steel(25) | Electric guitar | jazz(26), overdriven(29) |
| Strings | violin(40), string ensemble(48) | Ensemble | synth strings(51), string ensemble(48) |
| Brass | Trumpet(56), brass section(61) | Reed | bassoon(70), clarinet(71) |
| Pipe | flute(73), piccolo(72) | Lead | square(80) |
| pad | choir(91) | Effects | echoes (102) |
| Ethnic | sitar(104), shamisen(106) | Percussion | synth drum(118), taiko(116) |
| Drum | drum kit(0, is_drum=True) | Unknow | grand piano(0) |
There are significant differences in the note distribution of multiple instruments. We recommend proactively telling the model which instruments need to be created, and during the training phase, a strong relationship between the instrument label and note events must be established.
In our experiments with the official SymphonyNet implement, asking the model to grasp note distribution without condition in a multi-instrument dataset was awkward(such the characteristic of strings, ensemble and lead was ambiguous), and using the network to reclassify instruments on the generated tracks produced secondary deviation.
Therefore, according to our extensive experiments, it is necessary to make the instrument labels appear repeatedly in the representation sequence during the model training process, and preferably as input conditions during the inference process.
Tempo
Simply put, tempo determines how quickly the score is played, it is a significant global mark on score. The detailed explanation can be found at https://en.wikipedia.org/wiki/Tempo
Tempo affects the distribution of note onset times and durations, thus having a powerful influence on the emotion and mood. Therefore, we recommend using tempo as input condition for generation rather than letting the AI model choose on its own.
We divide the Tempo into 5 types according to bpm range:
| Tempo Type | BPM Range |
|---|---|
| largo | <66 |
| andante | 66-108 |
| moderato | 108-126 |
| allegro | 126-168 |
| presto | >168 |
Chord
In Pop-Diffuseq, Chord progression is the timeline of entire musical scores. Chords include 12 root notes and 9 types:
Major triad, Minor triad, Augmented triad, Diminished triad, Dominant seventh, Major seventh, Minor seventh, Half-diminished seventh.
Representation demo
A multi-instrument score is shown in Figure 4, and its corresponding representation sequence is below the score.

Figure 4. Music score.
Music content sequence Wm = [[chord, time0, chord-0-, reserve], [melody, time0, C5, dur2], [melody, time4, C5, dur2], [melody, time8, G5, dur2], [melody, time12, G5, dur2], [bass, time0, C4, dur8], [strings, time0, E4, dur2],
[strings, time4, G4, dur2], [strings, time8, E5, dur2], [strings, time12, C5, dur2],
[chord, time16, chord-2-m, reserve], [melody, time0, A5, dur2], [melody, time4, A5, dur2], [melody, time8, G5, dur4], [melody, time16, F5, dur2], [melody, time20, F5, dur2], [melody, time24, E5, dur2], [melody, time28, E5, dur2], [bass, time0, F4, dur4],
[bass, time8, C4, dur4], [bass, time16, F4, dur4], [bass, time24, C4, dur4], [strings, time0, D5, dur2], [strings, time4, D5, dur2], [strings, time8, C5, dur4], [strings, time16, D5, dur3], [strings, time22, D5, dur1], [strings, time24, C5, dur3], [strings, time30, C5, dur1],
[chord, time32, chord-3-m7, reserve], [melody, time0, D5, dur2], [melody, time4, D5, dur2], [bass, time0, G4, dur4], [strings, time0, D5, dur2], [strings, time4, E5, dur2],
[chord, time8, chord-0-, reserve], [melody, time0, C5, dur4], [bass, time0, C4, dur4], [bass, time0, E4, dur4], [bass, time0, G4, dur4], [strings, time0, C5, dur4]]
Supplement for Loss function
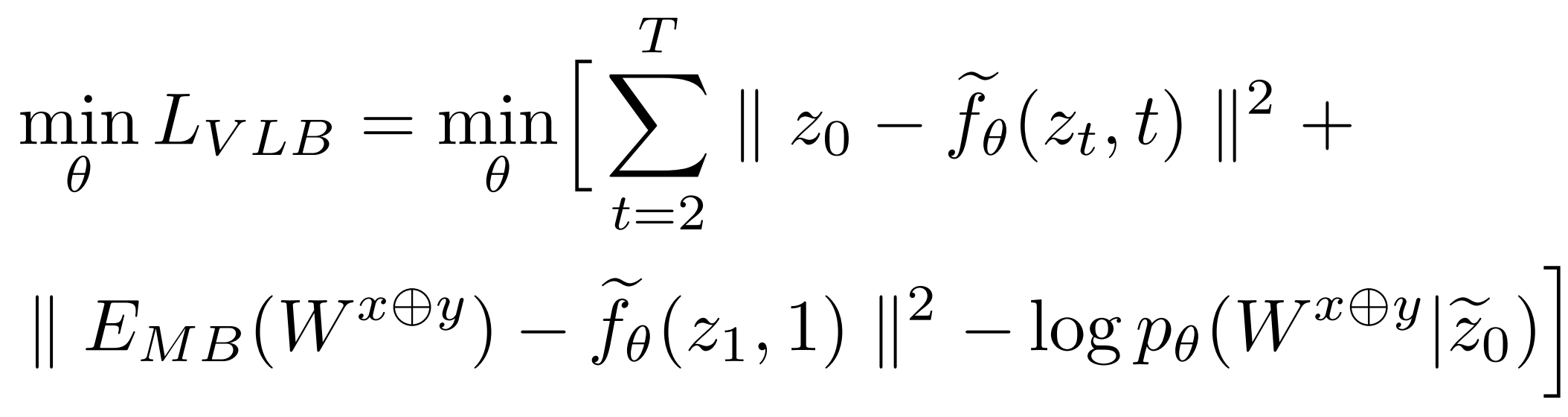
The definitions of functions and parameters are the same as those of the classic text diffusion model(Diffuseq, Difformer). The parameters x and y are common variables, they can be different things in different build tasks. In the controllable filling and accompaniment generation task, the x and y are c (condition) and m (music), respectively, in no particular order.
Input content embedding and output module
Some notable differences between our model and GPT-like textual models are the contextual (music content) embeddings and the output module.
As shown in Figure 5 (left), Embedding is used to convert integer event tokens into floating-point embedding vectors.
The size of 3D embedding tenser for a piece of music is [𝑖, 𝑗, 𝑑], where 𝑖, 𝑗, 𝑑 are the length of notes plus prompts, attributes and embedding vector.
At the end of framework, we design an output module that combines multiple linear layers and classification masks for structurally aligned tensors.
This module is used to map the encoder hidden state to a certain attribute category absolutely correctly.
For example, the hidden vector belonging to the pitch-dimension(third column) in the tensor must be mapped to one of 72 categories of pitch, and not be classified into duration or other categories.
The output module is shown in figure 5 (right).
Linear layer (colored trapezoids utilize a fully connected network to convert a hidden vector into an probabilities sequence of the same length as the dictionary(vocab size),
which reflects the probability scores of the tokens.
We divide hidden state tensor into 4 blocks by column(attributes), and arrange 4 linear layers to predict their respective probability scores.
The cross-modal information is concatenated with the first block (instrument attributes) and fed into the first linear layer.
Obtained probabilities is then multiplied bitwise by a 0-1 masking sequence 𝑀𝑎𝑠𝑘 𝑗 .
Tokens with probability scores set to 0 will not be selected.
Finally, the predictions are concatenated based on the grammatical structure of the representation.
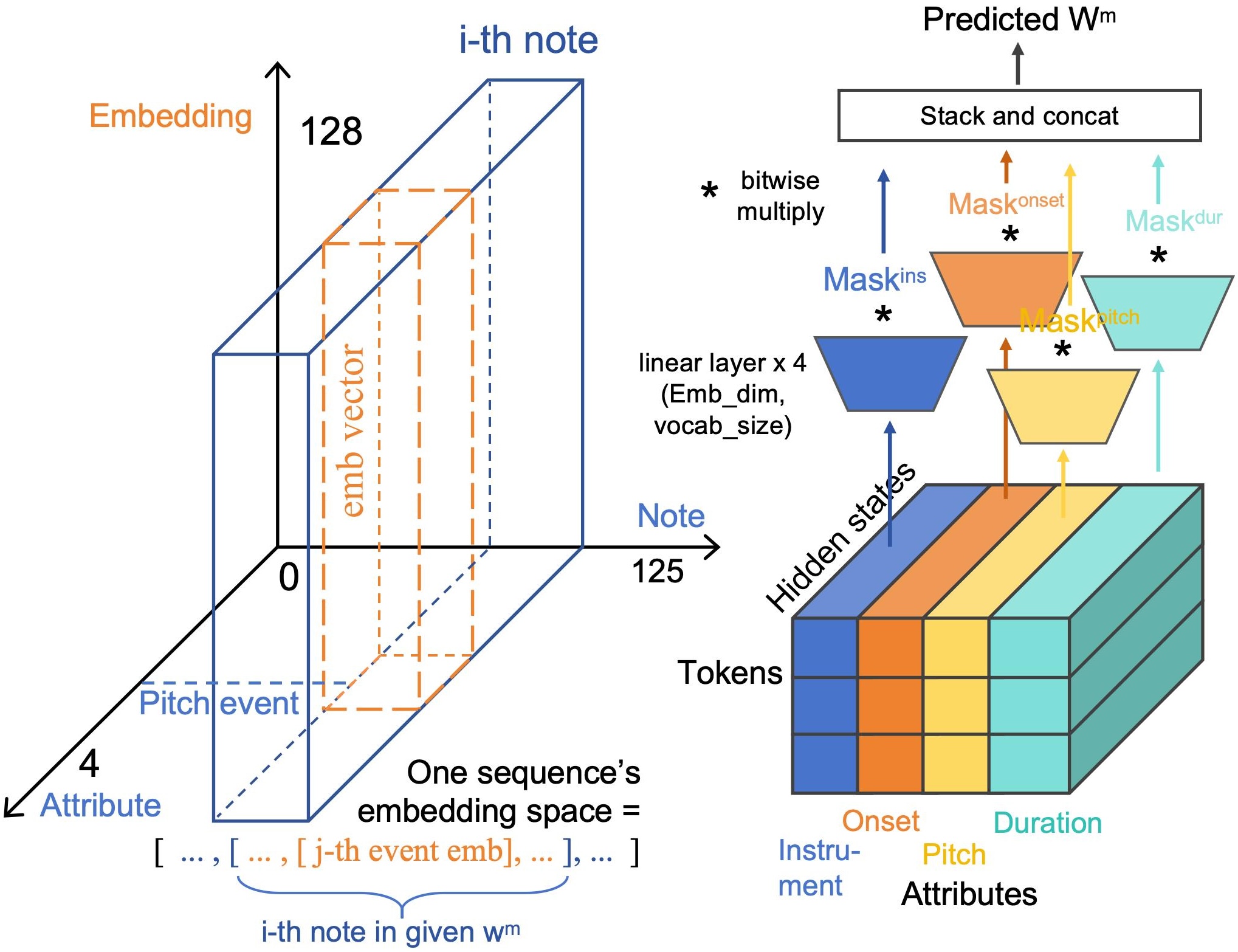
Figure 5. Input content embedding method and output module.
Objective evaluation supplement
(A) Model perplexity (PPL). We calculate token-wise PPL on the Validation set (different with train set). The lower the PPL index, the better. In all the Diffuseq-based comparison sets, we employ the same hyperparameter(layers, heads number of attention, embedding shape, etc.) in different model settings. The total stage of PPL curves are present in Figure 6. Compared to the baseline, our Pop-Diffuseq (green curve) converges faster, has lower PPL in the stable phase, and overfits later. The PPL curves of all settings in the stable phase are shown in the Figure 7. Pop-Diffuseq maintains the steady(variance<0.237) lowest value and is 55.89% lower than the average value of the baseline DiffuSeq (purple curve) over 8 valid recording points. On the contrary, DiffuSeq is unstable(variance>13 in converge phase) and fluctuates greatly throughout the training process. The DiffuSeq with la-attention(red curve) are lower than baseline DiffuSeq, indicating that la-attention can improve the fitting of model but is still unstable. The multi-head output module and modified objective function are helpful for the Pop-Diffuseq. In fact, we first reproduced the decoder-based SymphonyNet with linear transformer (same layers, heads and embedding shape, etc.) and MMR method, but their Loss and PPL metrics could not converge to a suitable interval in accompaniment task.
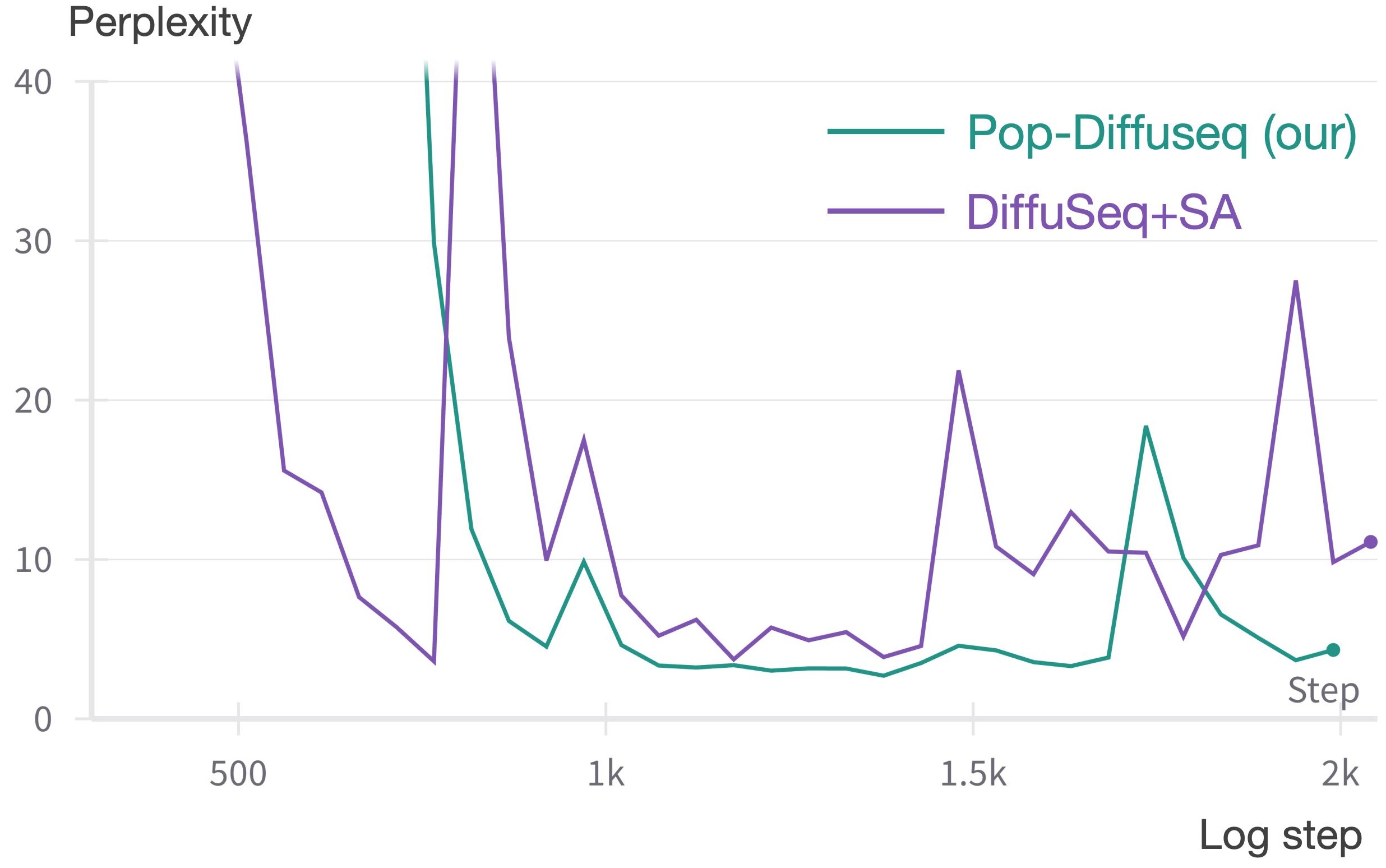
Figure 6. PPL curve for total stage. The lower the PPL index, the better.
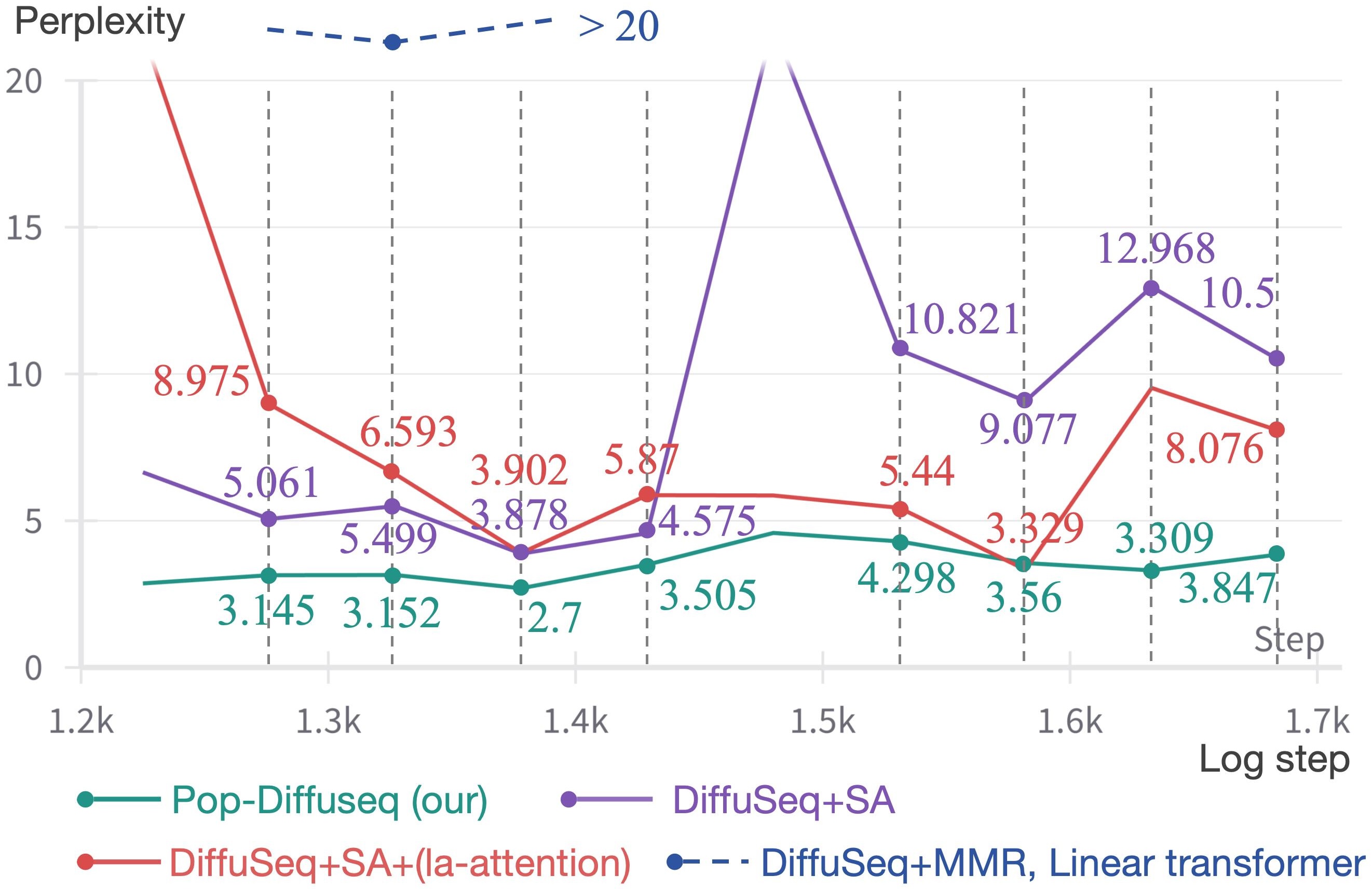
Figure 7. PPL curves of all settings in the stable phase. The lower the PPL index, the better.
(B) Objective evaluation for symbolic music. Figure 8-17 shows the pitch class transition matrix (PCTM), pitch classes histogram, average duration and onset interval for generated and reference instruments on test data set. Reference instrument means the human created music in test data set. The result shows that our POP-diffuseq correctly produces musical content under the requirements of instrumental prompts, and the generated content has both the characteristics of instruments and the richness of AI.
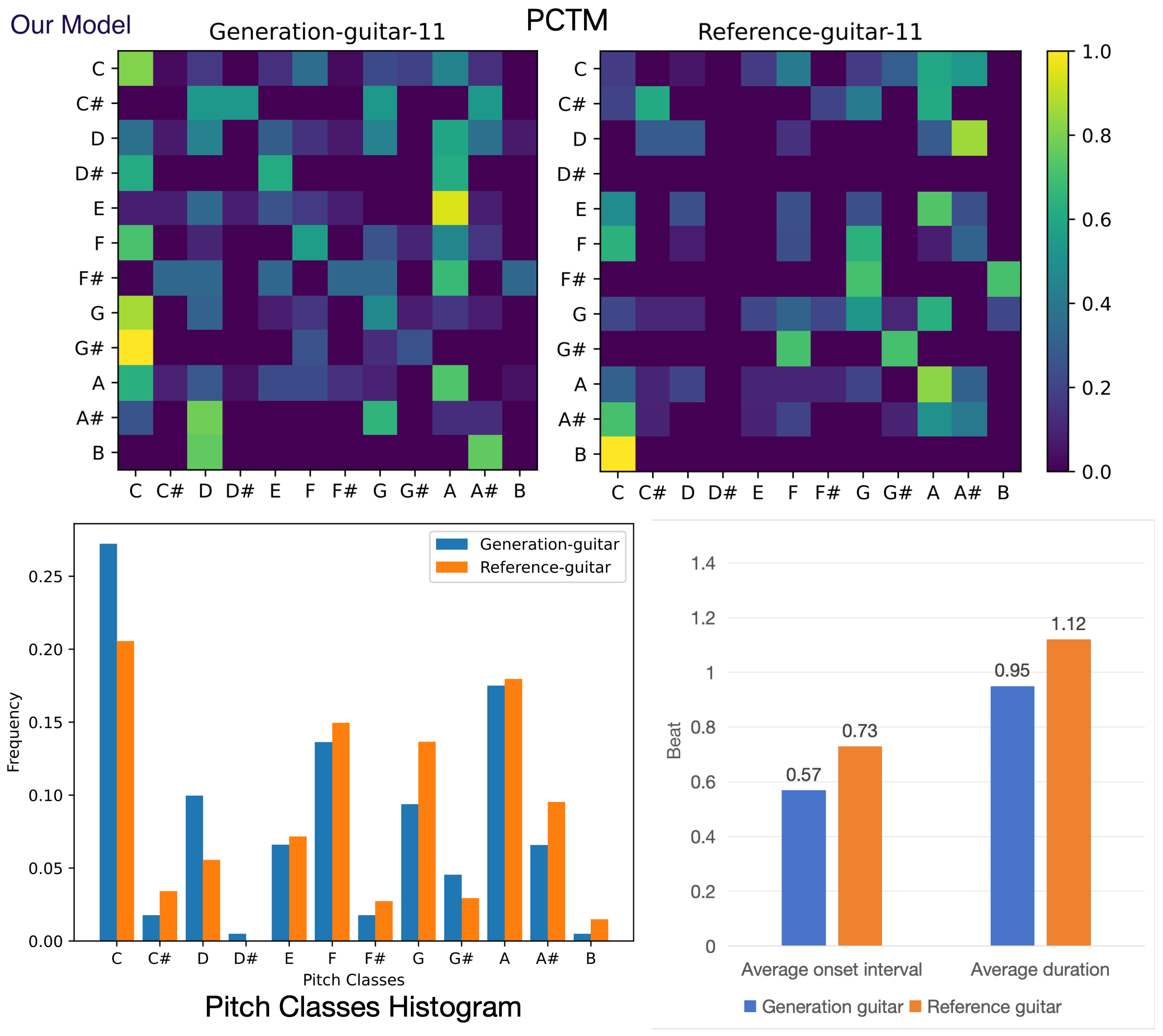
Figure 8. Objective evaluation for generated and reference guitar.
The generated guitar are present by our model.
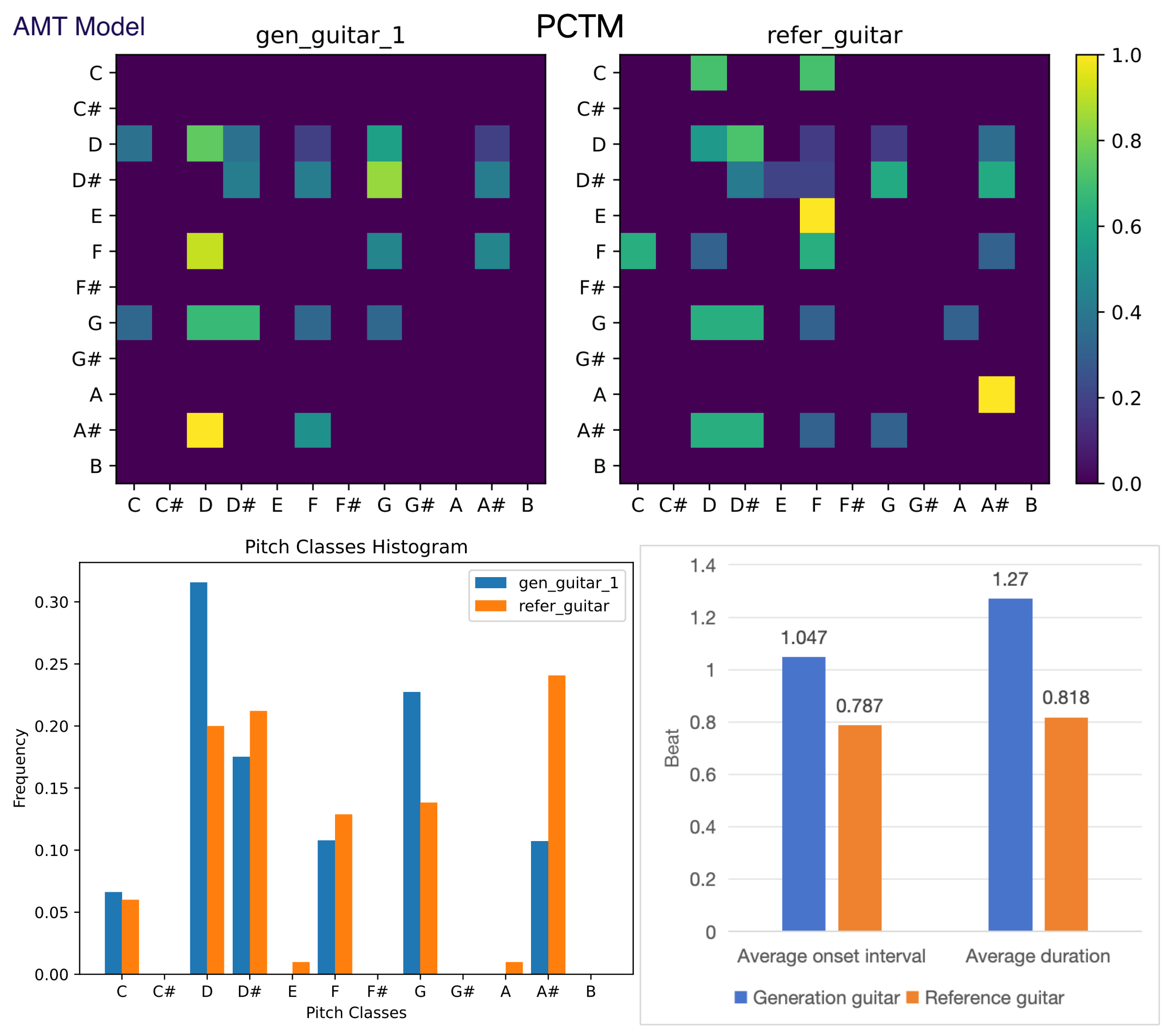
Figure 9. Objective evaluation for generated and reference guitar.
The generated guitar are present by AMT model.
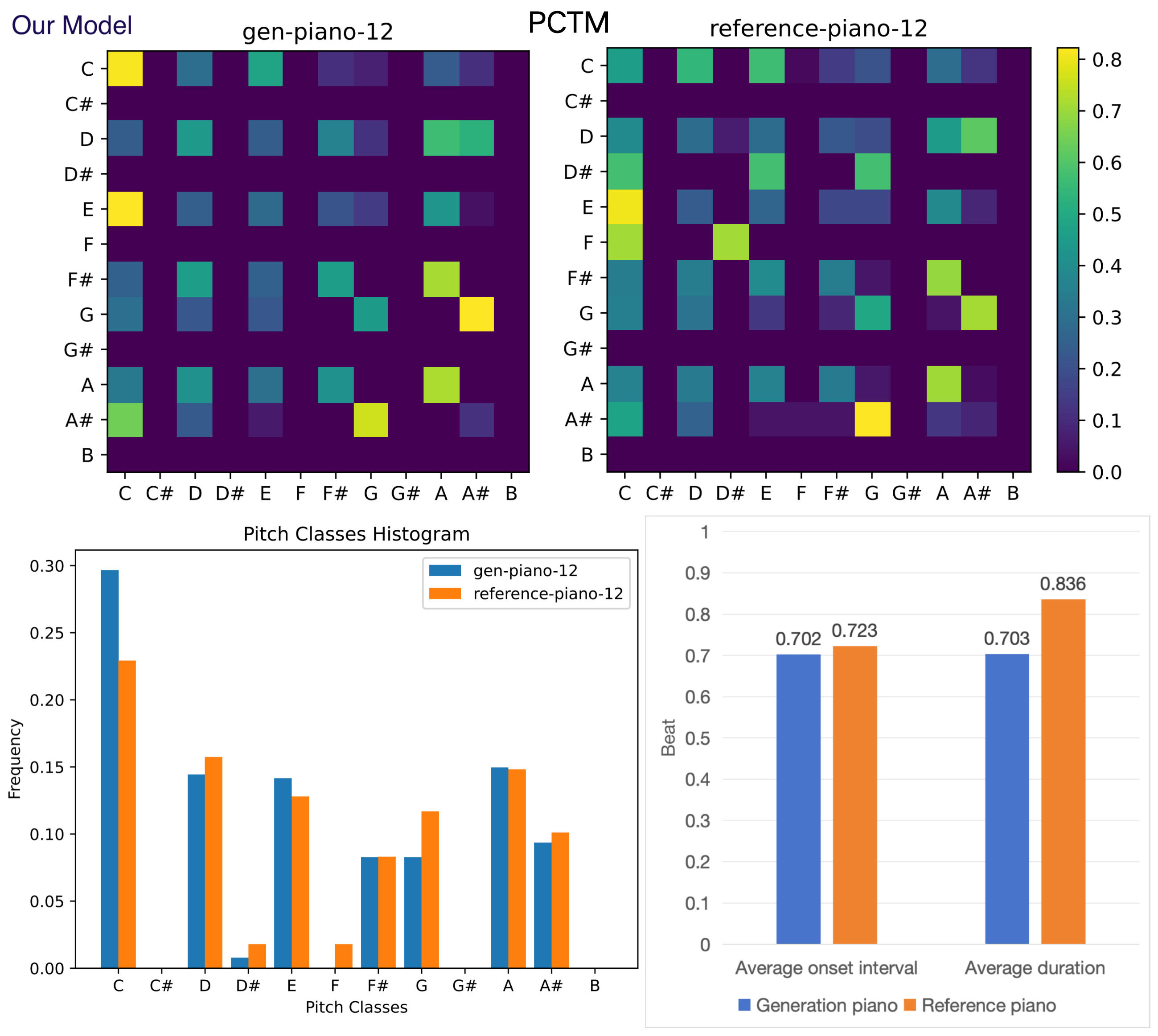
Figure 10. Objective evaluation for generated and reference piano.
The generated piano are present by Our model.
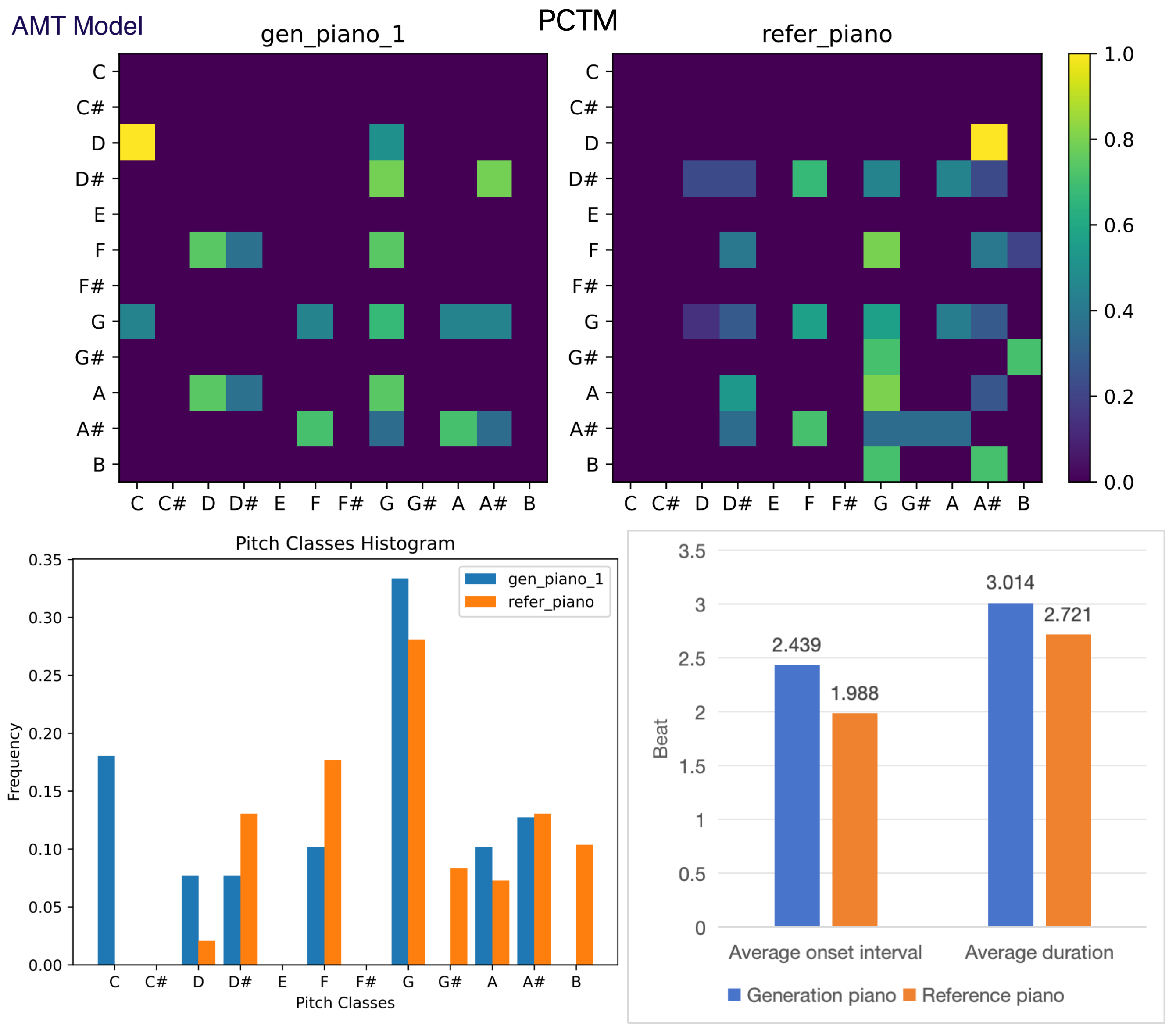
Figure 11. Objective evaluation for generated and reference piano.
The generated piano are present by AMT model.
Figures 8 to 11 show two groups of comparative tests.
Two models are compared, one is our model (Pop-diffuseq) and the other is the latest SOTA model AMT which is published in the Transactions on Machine Learning Research, 2024.
They are both trained and evaluated on the LMD dataset.
The generated and reference samples of AMT are obtained by the official Colab Notebook: https://johnthickstun.com/anticipation/
Figures 8 and 9 are a pair of guitar tests. Figure 10 and 11 are piano tests.
Regarding PTCM, Pop-diffuseq is competent for more complex content,
and the images of generated PTCM are richer for AMT, indicating the richness of our model.
Both models can learn the characteristics of the instrument because the shape of the generated PTCMs are equivalent to the references.
For pitch classes histogram, average duration and onset interval,
the more similar the generated histogram is to the reference, the better.
The Pop-diffuseq model handles the characteristics of musical instruments better.
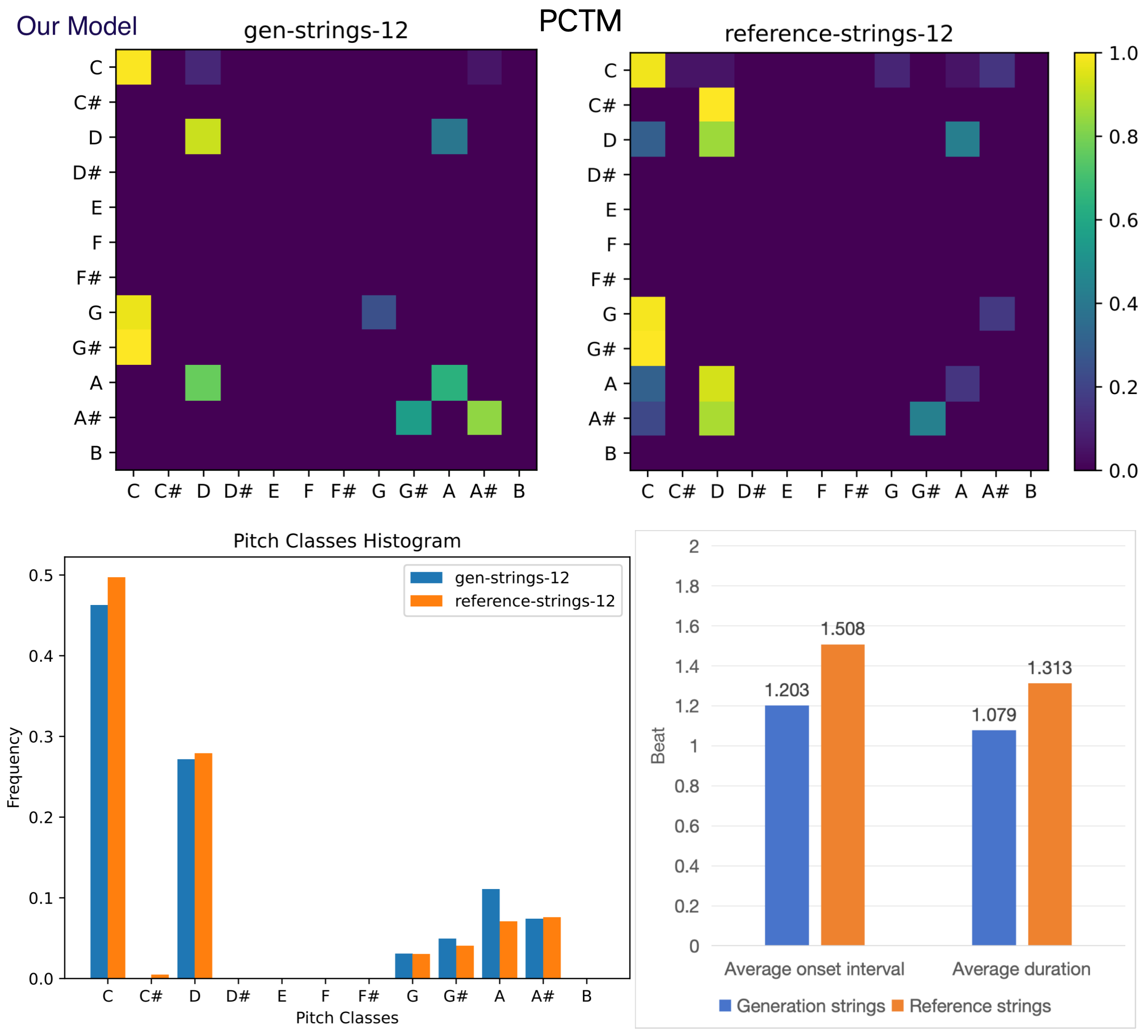
Figure 12. Objective evaluation for generated and reference strings.
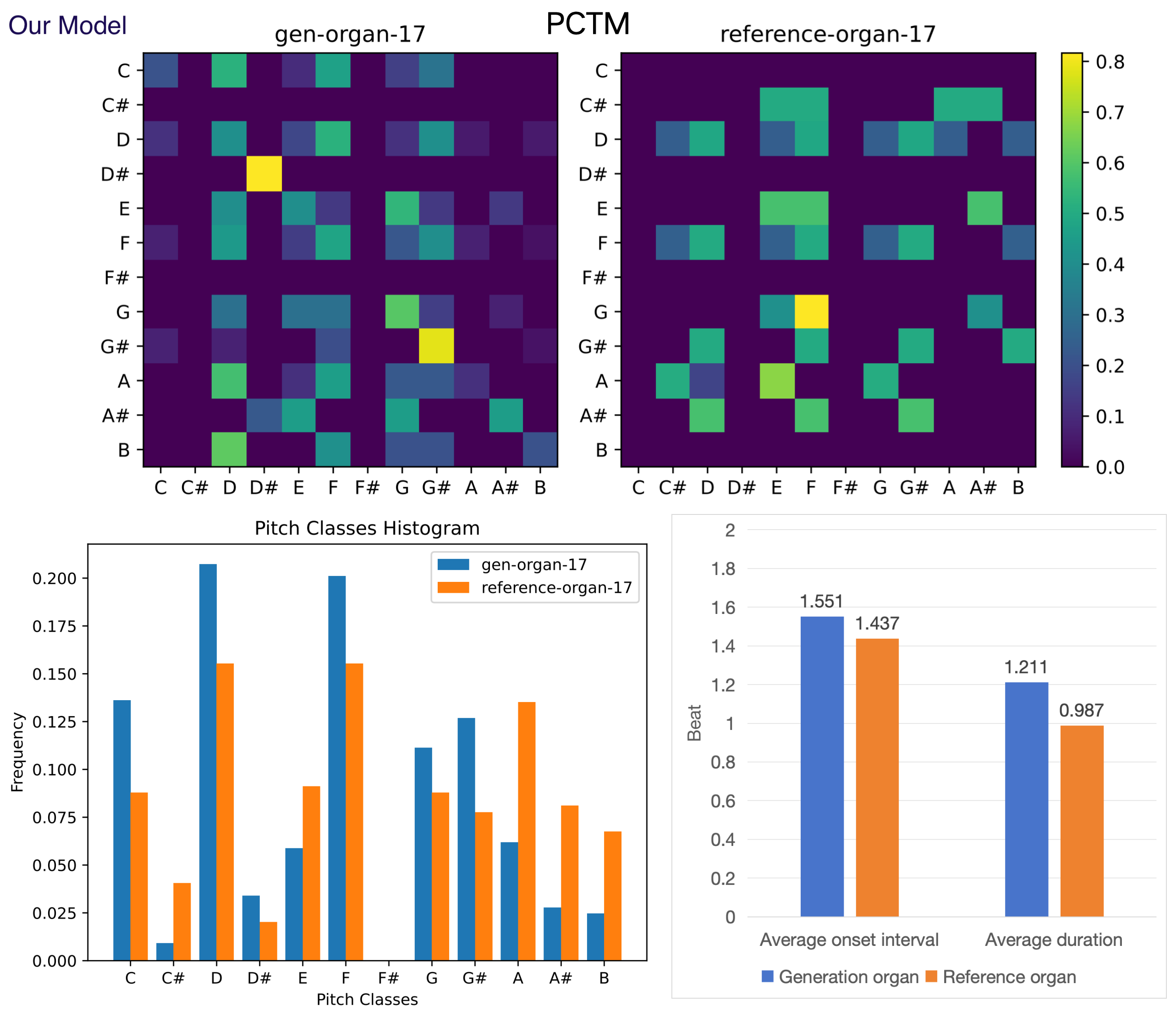
Figure 13. Objective evaluation for generated and reference organ.
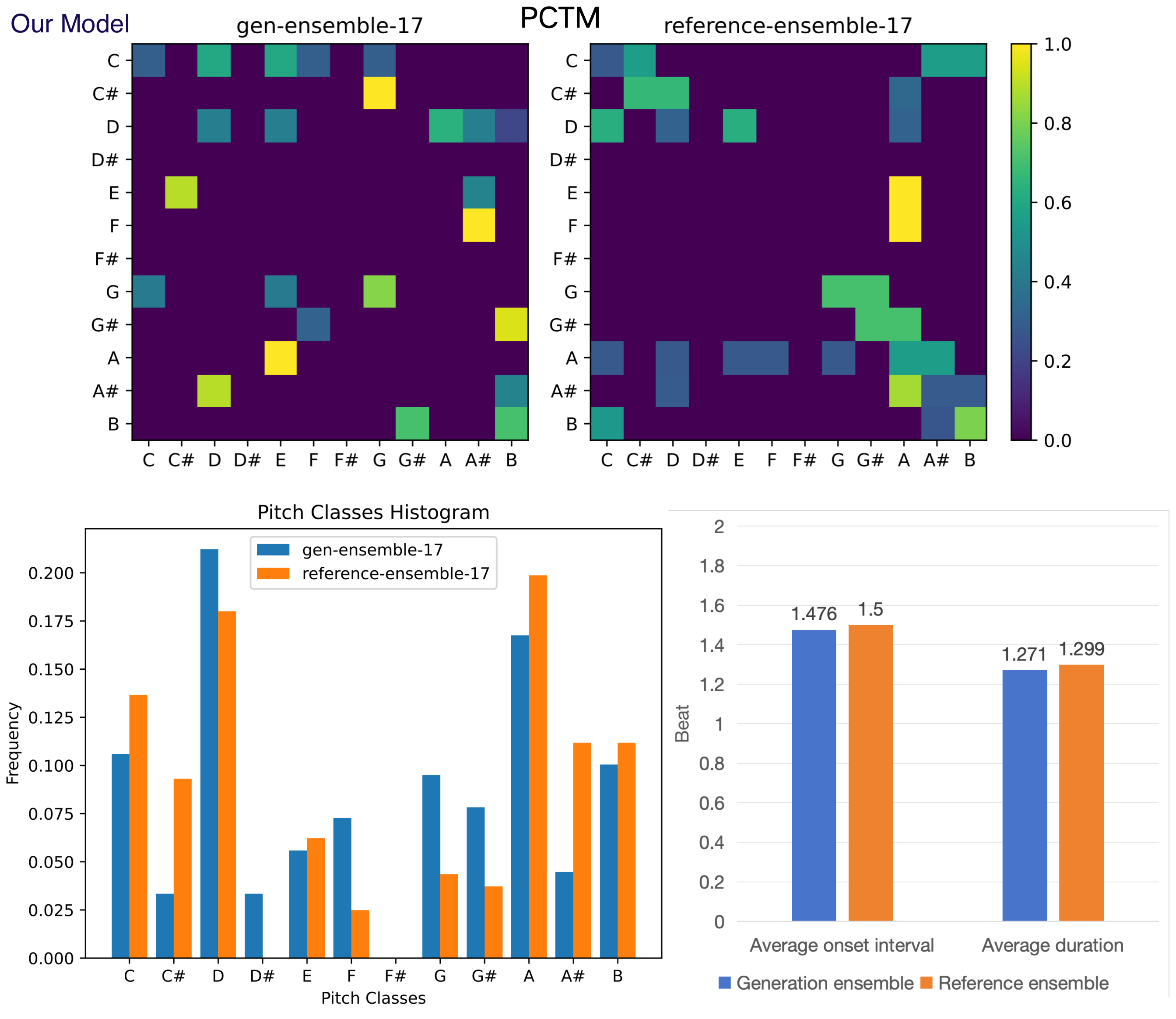
Figure 14. Objective evaluation for generated and reference ensemble.
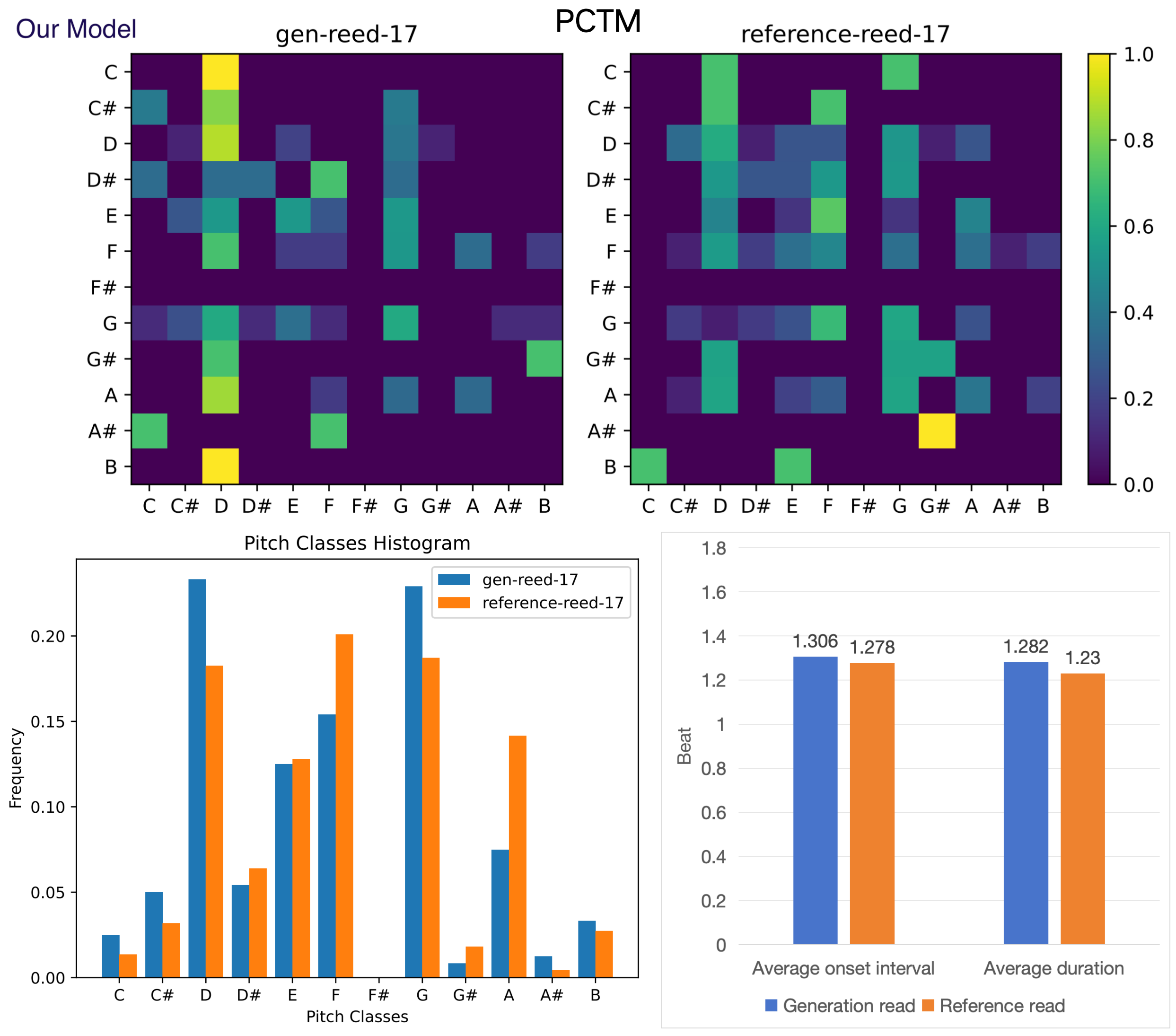
Figure 15. Objective evaluation for generated and reference reed.
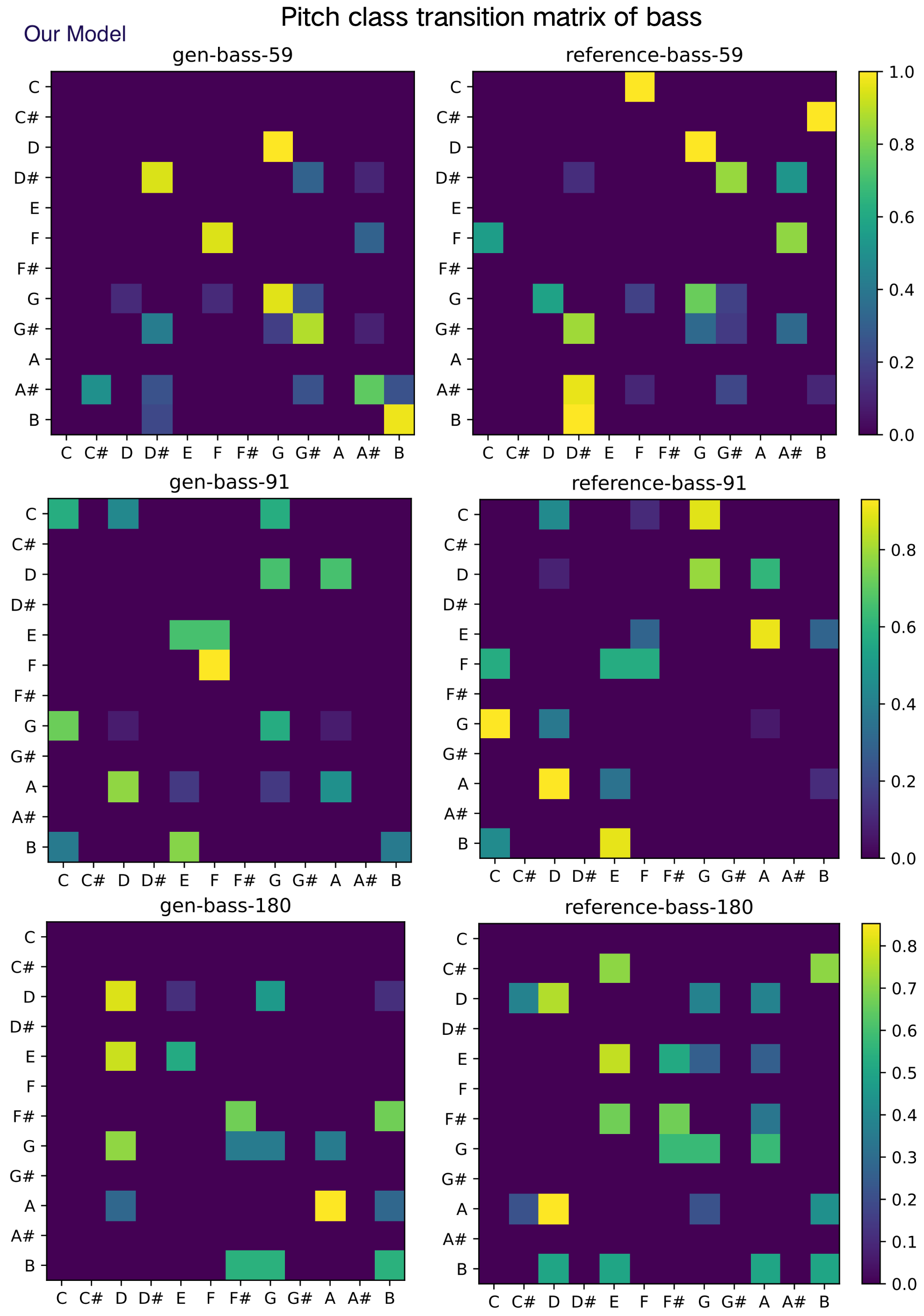
Figure 16. The pitch class transition matrix for 3 sets of bass.
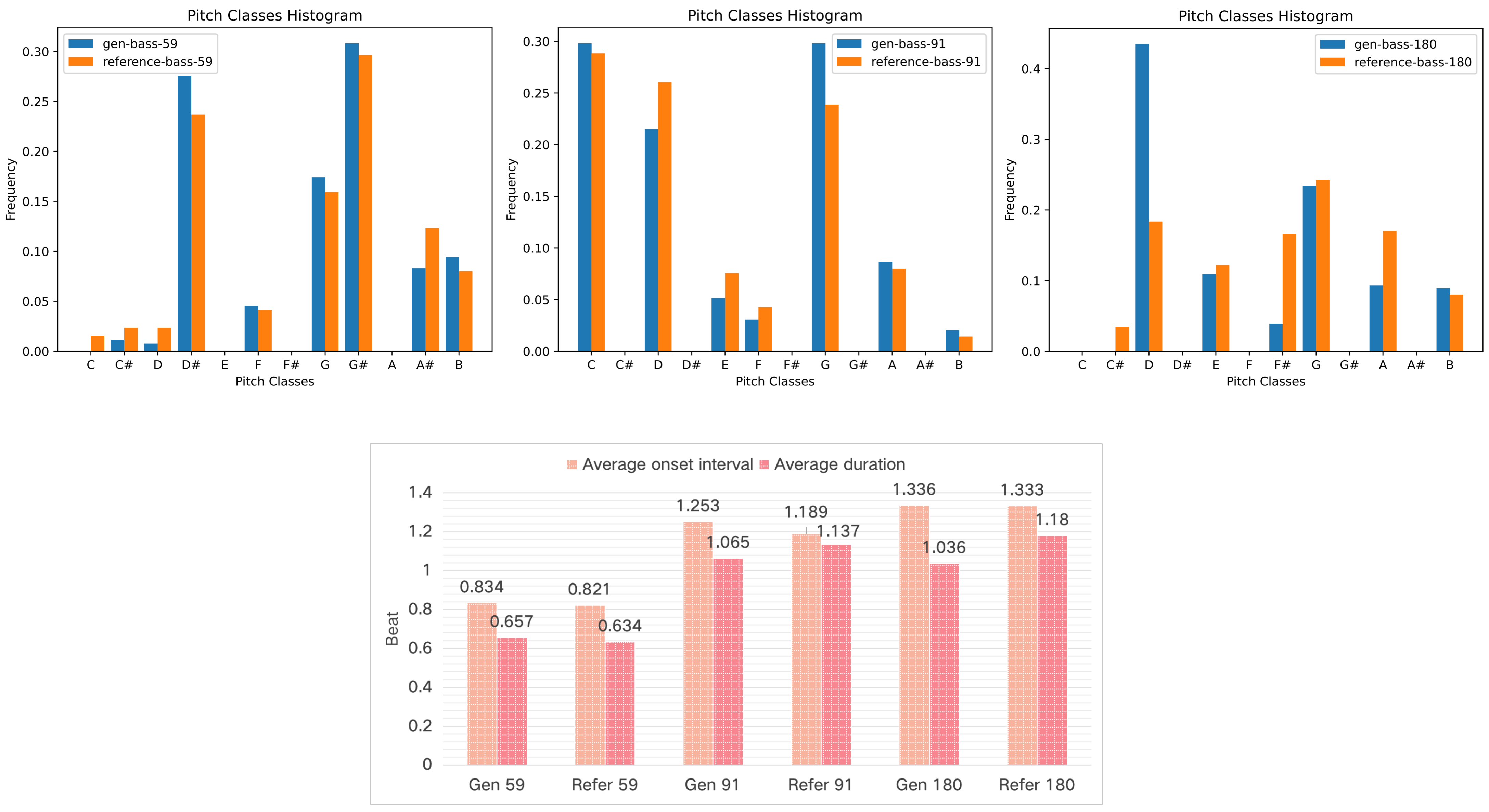
Figure 17. The pitch classes histogram, average duration and onset interval for 3 sets of bass.
Figures 12 to 17 present various samples of musical instruments created by our model. They are randomly selected, not hand-picked, and you can reproduce them using our public code and platform. These images show that our model can well mimic the characteristics of human-composed musical scores, which is of great value for commercial applications.
In the end
Thank you so much for reading this, and thank you for your time and patience!
Wishing you all the best in 2025!
Happy New Year!